Learning Invariant Representations
In machine learning, models need to learn to ignore unimportant or even distracting features. These are typically features that correlate with target labels in the training data - but not the test data. Generalisation is, after all, the goal of most machine learning algorithms. It requires a trade-off between (1) sensitivity to relevant features in the data and (2) methods to suppress distractions. My research addresses the second point. More specifically, it focuses on ways of directly modelling invariance so as to suppress unimportant or distracting features and improve overall performance.
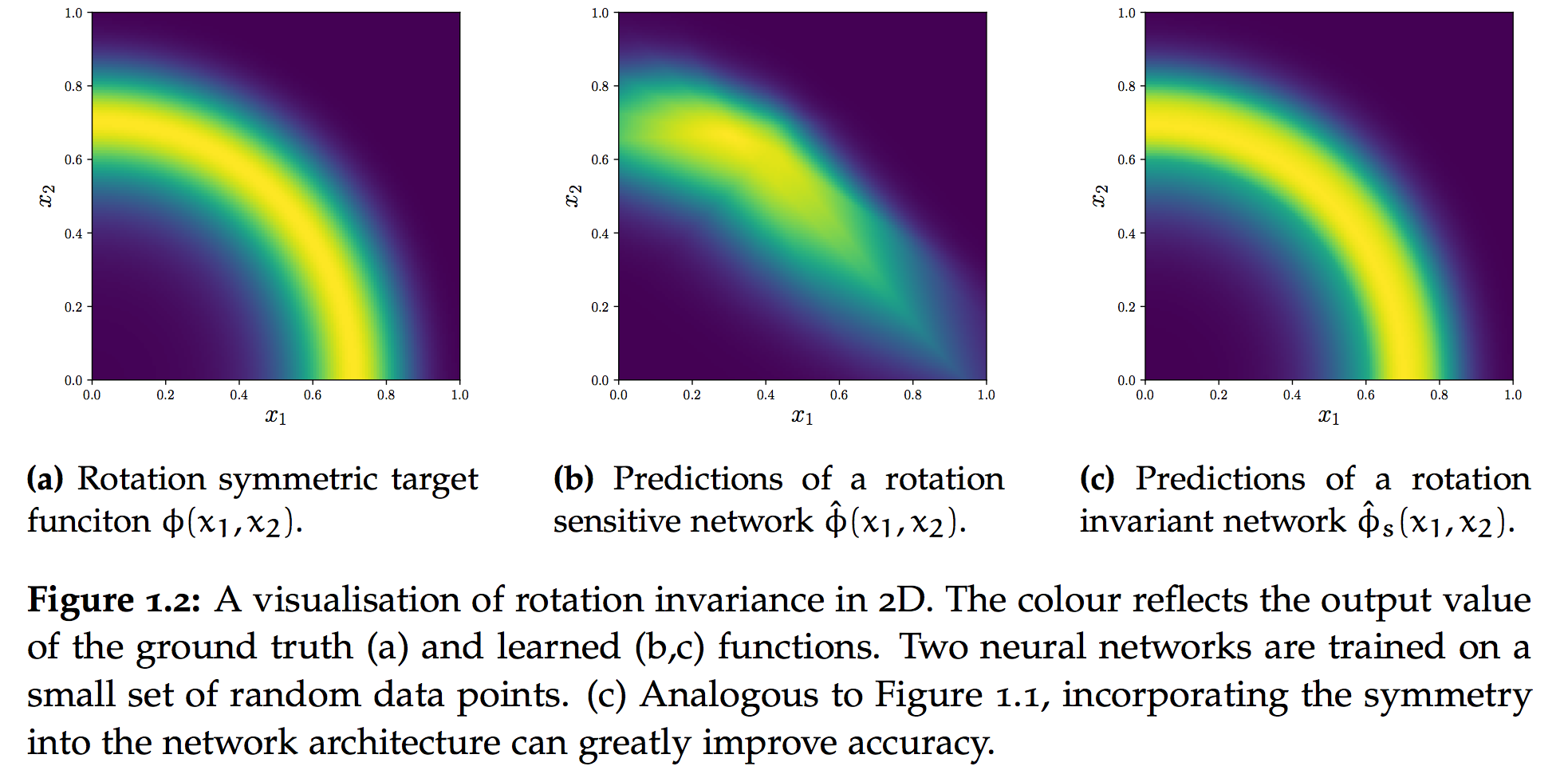
Arguably the most wide-spread way of suppressing noisy features in the input is regularisation, which aims at mitigating overfitting. Examples include weight decay, early stopping or dropout. These techniques share the underlying principle of Occam’s razor, which is indispensable in machine learning and key for good generalisation. However, my research focuses on more targeted forms of invariances. A helpful tool to formulate this more concretely is the concept of task symmetries as described in Mallat 2016. Here, a global symmetry is defined as an invertible operator $g: \mathcal{V} \to \mathcal{V}$ which, applied to the input of a function $\phi : \mathcal{V} \to \mathcal{Y}$, does not change its result
$\phi(g\circ v) = \phi(v) \quad \forall v \in \mathcal{V}$
If the above holds for invertible operators $g_1$ and for $g_2$, then the composition $g_1\circ g_2$ is also an invertible symmetry operator, implying that the operators form a group under composition. Concrete examples of such symmetries are permutations of a set or rotations of a point cloud. It is worth pointing out that the above defines a symmetry as a property of a task, not a dataset. For instance, let the dataset be a collection of indoor objects represented as point clouds. Each point is simply an x-y-z coordinate. If the task is to predict whether the object is a table or a chair, the task is symmetric or invariant with respect to global rotations of the points. However, if the task was to predict whether the object is in an upright position or upside-down, rotating the point cloud could certainly change the desired output.
Permutation Invariance

Examples of permutation invariant tasks in deep learning are plentiful: point cloud classification, relational reasoning about multiple objects in an image or regression tasks on a group of atoms which together form a molecule. In all of these tasks, the practitioner has to feed a collection of inputs - e.g., the points of a point cloud - into a neural network. Critically, these collections have no intrinsic ordering, despite the fact that they are normally represented as a list in common programming languages. In other words, these tasks are symmetric with respect to all permutations, which together form a symmetry group. Feeding these lists to a fully connected layer would not respect this symmetry. The network would have to learn to become permutation invariant. This raises the question how to construct neural networks which are intrinsically permutation invariant.
In On the Limitations of Representing Functions on Sets, we examine DeepSets, a widely used permutation invariant architecture. We provide sufficient and necessary condition for the construction of such a network to guarantee universal fucntion representation.
One example of a permutation invariant (or equivariant) task is relational reasoning. In End-to-end Recurrent Multi-Object Tracking and Trajectory Prediction with Relational Reasoning, we examine the importance of relational reasoning and the role of permutation invariance in a real-world setting.
Roto-Translation Invariance
In the previous section, we examined how to design a network that handles the permutation invariant structure of point clouds appropriately. However, tasks on point clouds often exhibit additional symmetries: rotations and translations. Interestingly, most popular deep learning algorithms for point clouds do not fully leverage these additional symmetries and hence fail to incorporate an inductive bias about geometry. With the SE(3)-Transformer, we introduce a variant of the self-attention module for 3D point clouds, which is equivariant under continuous 3D roto-translations.
Label Invariance

In the beginning, we stated that a symmetry of a task is defined through a symmetry operator $g$ with $\phi(g\cdot v) = \phi(v) \; \forall v \in \mathcal{V}$. In this section, we look at cases where our knowledge about the operator $g$ is very limited. We only know that $g$ changes a property of $v$ and we know that $\phi(v)$ is invariant with respect to that property. Furthermore, we assume a setup in which this property is known during training time, at least for some examples. In other words, label invariance describes the invariance of a task with respect to a property of the input for which we have labels during training time.
An intuitive example for this setup is robustness versus domain shifts. When training an object detector on images, it might be desirable to achieve robust performance across multiple domains, such as different camera angles, inside vs. outside or day vs. night. Moreover, training data is typically limited and in general not equally distributed across domains. Hence, in order to achieve maximum sample efficiency, it is a promising strategy to enforce the network to extract features from the input which are independent of the domain. With Neural Stethoscopes, we introduce a tool which allows for suppressing and promoting information that is correlated with a specific label.
Credit: I am doing my PhD at A2I (Oxford University), supervised by Ingmar Posner and in collaboration with Adam Kosiorek, Alex Bewley, Andrea Vedaldi, Daniel Worrall, Edward Wagstaff, Li Sun, Martin Engelcke, Markus Wulfmeier, Max Welling, Michael Osborne, Oiwi Parker Jones, Oliver Groth, Volker Fischer. I would like to thank the EPSRC as well as Kellogg College Oxford for funding.